摘要:隨着改革開放的不斷深入,居民家庭的收入水平和生活水平不斷提高,對家庭資産配置有了更高質量的要求。資産配置涉及資産定價和投資優化組合等問題,已經成為數理統計、機器學習、行為金融等多學科的交叉研究熱點。合理的資産配置策略不僅能夠為投資者們帶來可觀的超額收益,還能促進資本市場健康發展和維護國家金融安全。大多數居民的投資策略基於歷史投資經驗、宏觀市場的及時信息和個人的想法,難以隨外界變化而靈活變通。人工智能、雲計算、大數據等科學技術正重塑資産配置模型,運用相關技術可以提供更全面準確的信息分析,優化資産配置模型與策略,提升投資決策的效率與質量,從而在可控風險的條件下取得穩健收益,實現居民財富的保值增值目標。本文重點關注決策樹和深度學習算法在資産定價問題上為居民資産配置提供的解決方案,並在中國A股市場的幾個關鍵指數上驗證了模型的有效性。本文的貢獻如下:其一,基於LightGBM的決策樹模型與傳統多因子組合模型相比,具有可解釋性強、數據質量要求低等特點,在滬深300和A500的指數成分股上運用純多頭策略實現了年化收益率約7%和2%的提升;其二,基於Transformer的深度學習模型與其他深度模型相比,通過自注意力機制可以挖掘更深的隱含關係具有更強的非線性擬合能力,在滬深300和A500的指數成分股上相比ALSTM(基於注意力的長短記憶網絡)實現了年化收益率0.7%和1%的提升。相關算法的研究豐富了證券公司智能投顧&&的資産配置策略,為居民提供了多樣化的財富管理方案。
1.引言
本世紀以來,我國居民財富積累速度加快,其中房地産佔家庭財富的比例高達80%,大幅領先以股票、基金為代表的權益類金融資産佔比。在財富管理市場,銀行理財佔比高達50%,遠遠高於基金、信託和保險資管等産品的比例。該現象與國際上成熟的財富管理市場截然相反。黨的二十大報告中強調中國式現代化是全體人民共同富裕的現代化,而居民財富的保值增值是實現共同富裕的重要途徑之一。隨着近年來我國對房地産市場的科學調控以及銀行存款利率跌破2%,居民將擠出更多存款向資本市場傾斜。
合理的資産配置策略不僅能夠為投資者帶來較為可觀的超額收益,同時對於促進資本市場健康發展和維護金融安全具有重要現實意義。大多數居民的投資策略是基於歷史投資經驗、宏觀市場的及時信息和個人的想法,難以隨外界變化而靈活變通;此外投資標的急劇增加以及標的信息的大爆炸導致傳統的資産配置策略面臨着資産數量維度大和投資信息集維度高的挑戰,因此構建適應當前時代投資需求的資産配置方法顯得尤為必要。
人工智能、雲計算、大數據等科學技術驅動着資産配置模型的轉型和重塑。通過對海量數據的挖掘,為居民資産配置提供更全面、深入的信息基礎;通過對風險承受能力和收益目標的平衡,為居民定制合理的風險控制方案;通過對市場動態的跟蹤,幫助居民及時調整資産配置策略,避免因信息滯後而導致的決策失誤。
面對金融市場非平穩和隨機的本質,機器學習能夠處理和分析非線性關係,通過過濾噪音和降低特徵維度發現隱藏的模式和趨勢,揭示傳統方法難以捕捉的複雜數據結構,提高策略的靈活性和準確性。決策樹模型相比傳統的特徵工程技術(例如主成分分析、奇異值分解和獨立成分分析等)能夠提供清晰的決策路徑和規則,可解釋性好;在處理輸入變量的異常值和缺失值上不需要嚴格的標準化數據,具有較強的魯棒性;在訓練和推理的過程中會自動篩選特徵的信息增益,有效避免無關或冗余特徵的影響。本文在股票上利用LightGBM樹模型對資産價格進行回歸和分類的嘗試,驗證了機器學習算法的有效性,緩解了人工篩選因子的難度,提升了資産定價的效率。
在海量數據的背景下,深度學習技術從卷積神經網絡 (CNN)、循環神經網絡(RNN)、圖神經網絡 (GNN)到現在以ChatGPT為代表的大語言模型(LLM),通過堆疊更多的參數層可以擬合更複雜的環境變量。以Transformer為代表的自注意力機制,作為大語言模型的核心技術,無論是在處理多資産橫截面收益分析的問題還是單資産時間序列預測的問題上都有很好的泛化性。本文在股票上利用Transformer編碼器從時間和空間兩個維度分析資産收益,通過自注意力機制捕獲資産本身在時間上的動量效應以及資産相互間的價格傳導機制,實現了更準確的價格預測,擴展了傳統投研方法的邊界。
綜上,對於資産定價,本文探索了以LightGBM為代表的決策樹模型和以Transformer為代表的深度神經網絡在股票價格趨勢預測上的非線性擬合能力。
2.相關工作
2.1資産定價
在不確定條件下資産未來風險與收益之間的權衡關係是資産定價(Asset Pricing)的核心問題。傳統資産定價模型主要有資本資産定價模型(CAPM)[1]和套利定價理論(APT)[2]。
CAPM是基於風險資産期望收益均衡基礎上的預測模型,它認為資産的預期收益率等於無風險利率加上風險溢價,而風險溢價取決於資産的系統性風險:
![]()
其中E(Ri)是資産i 的預期收益率,Rf是無風險利率,資産的貝塔系數βi衡量資産相對於市場組合的系統性風險,E(Rm)是市場組合的預期收益率。
APT認為資産的預期收益率取決於多個因素,而不僅僅是市場組合的收益率。它通過構建多因素模型來解釋資産的收益:
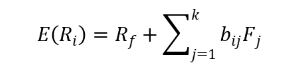
其中bij是資産i對第j個因素的敏感度,Fj是第j個因素的風險溢價,k是風險因素的數量。如果資産的定價不合理,就會出現套利機會,投資者會通過套利行為使資産價格回歸合理水平。
Fama-French三因子模型[3]認為股票的收益率除了受市場風險因素影響外,還受到公司規模、賬面市值比等因素的影響。套利定價理論為三因子模型的發展提供了理論基礎,Fama-French三因子模型是在套利定價理論基礎上的具體應用和拓展。Fama-French多因子模型還存在盈利水平風險、投資水平風險等其他因素影響股票的收益率。隨着數據的豐富和計算能力的提升,大量的因子被挖掘出來,用於解釋資産價格或投資組合的表現,就如同一個“動物園” 裏有各種各樣的因子——“Factor Zoo”。這些因子來源多樣、數量眾多且特性各異,主要分為市場因子、規模因子、價值因子、盈利因子、投資因子等。
2.2機器學習
金融數據和因子的幾何式增長對傳統資産定價和組合管理模型的參數估計、有效性都充滿了挑戰。隨着深度學習的提出和硬體算力的提升,金融領域也正在迎接“大數據+深度模型”的時代。金融數據具有非線性、非平穩性和高噪音性三大性質,這對於傳統統計學方法是苦難的,但機器學習不需要複雜的數據預處理,能夠通過大量樣本的訓練保證模型的泛化能力。
其中集成學習算法將多個弱學習器通過各種投票機制構建成一個強學習器的模型,在圖像識別、自然語言處理等領域都有廣泛應用。目前集成算法分為Bagging(袋裝法)和Boosting(提升法)兩類。Bagging以隨機森林為代表,通過對原始數據集進行有放回的隨機抽樣,得到多個不同的子數據集,然後分別在這些子數據集上訓練多個弱學習器(通常是決策樹),最後通過投票等方式將這些弱學習器的結果進行組合。Boosting以AdaBoost(Adaptive Boosting)、 GBDT(Gradient Boosting Decision Tree)為代表,是一種串行的集成方法,即依次訓練多個弱學習器,每個弱學習器都是基於上一個弱學習器的錯誤進行調整和改進。通過不斷地調整樣本權重和學習器權重,使得後續的弱學習器更加關注那些被前一個弱學習器錯誤分類的樣本,從而逐步提高整體模型的性能。微軟開發的LightGBM[6]採用了一系列優化技術,在訓練速度、內存佔用和準確率等方面具有明顯優勢,廣泛應用於信用風險評估、金融市場價格和趨勢預測等任務。
端到端的深度學習是一種直接從原始輸入數據到最終輸出目標的方法,無需手工設計中間步驟或特徵工程。它試圖通過構建深度神經網絡,讓模型自動學習從輸入到輸出的映射關係。它無須專業人員深刻複雜的先驗知識,取消了對數據和模型內部邏輯的複雜處理和設計。卷積神經網絡(CNN)、長短期記憶網絡(LSTM)[7]和Transformer[8]成為深度學習主流的模型架構,CNN 通過卷積層、池化層和全連接層等組合來提取二維空間數據的特徵;LSTM由遺忘門、輸入門和輸出門組成,解決了傳統 RNN(循環神經網絡)在處理長序列時面臨的梯度消失和梯度爆炸問題,用於處理序列數據;Transformer基於注意力機制,摒棄了傳統的遞歸和卷積結構,可以高度並行化計算大大加快訓練速度,無論是在長時間序列數據還是二維空間數據上都取得了非常好的效果。
3.研究方法
3.1 LightGBM
根據決策樹輸出結果的不同,決策樹可以分為分類樹和回歸樹兩類。其核心邏輯是根據度量標準,從樹根開始選擇最優特徵逐級分裂,遞推生成一顆完整的決策樹。業界大多使用信息增益(&&信息不確定性減少的程度,越大越好)、信息增益比(越大越好)、基尼系數(衡量集合的純度,越小越好)作為分裂標準。CART(Classification and Regression Tree)決策樹每次選擇基尼系數最小的屬性進行迭代,它既可以解決分類問題又可以解決回歸問題。決策樹在建立樹時如果參數選擇不合理(即樹根或者枝幹略有差池),樹就可能會徹底長偏,産生過擬合的現象,導致泛化能力變弱,因此大多會採用剪枝、交叉驗證等手段。除此之外,為了有效減少單決策樹帶來的問題,與決策樹相關的組合(比如Bagging, Boosting等算法)也逐漸被引入進來,這些算法的精髓都是通過生成N棵樹(N可能高達幾百)最終形成一棵最適合的大樹。如圖3-1所示,Bagging技術類似多數投票機制,對於不同的分類器可以通過並行訓練而獲得,且每個分類器的權重相等;但Boosting則是在前面已訓練獲得的分類器基礎上加以調整(更關心之前分類器分錯的樣本)而獲得新的分類器,因此Boosting中的分類器權重並不相等,其權重值代表該分類器在上一輪迭代中的成功度。總的來説Boosting主要關注降低偏差,能基於泛化性能相對弱的學習器構建出很強的集成;Bagging主要關注降低方差,在不剪枝的決策樹、神經網絡等學習器上效用更為明顯。GBDT(Gradient Boosting Decision Tree)是基於bagging的算法,通過構造一組弱的分類回歸樹CART,並把多顆決策樹的結果累加起來作為最終的預測輸出。所有弱分類器的結果相加等於預測值。每次都以當前預測為基準,下一個弱分類器去擬合誤差函數對預測值的殘差(預測值與真實值之間的誤差)。LightGBM是GBDT的算法實現,引入了並行方案、基於梯度的單邊檢測、排他性特徵捆綁等,提供一個快速高效、低內存佔用、高準確度、支持並行和大規模數據處理的數據科學工具。在本研究中,將股票的多因子特徵作為輸入,股票未來幾日的收益率作為標籤,通過決策樹擬合股票未來N天的收益率變化趨勢。
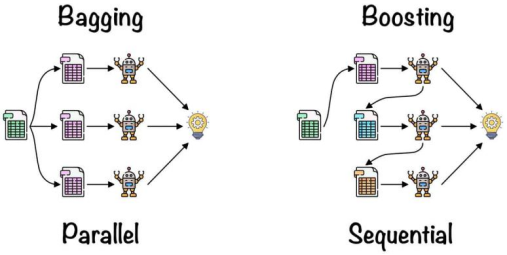
圖3-1 集成算法Boosting和Bagging的區別
3.2 Transformer
自從BERT(一種基於Transformer架構的深度學習模型)和GPT模型取得重大成功之後,Transformer結構已經替代了循環神經網絡(RNN)和卷積神經網絡 (CNN),成為了當前NLP模型(自然語言處理模型)的標配。如圖3-2所示,Transformer模型架構中的左半部分為編碼器(Encoder),右半部分為解碼器(Decoder)。
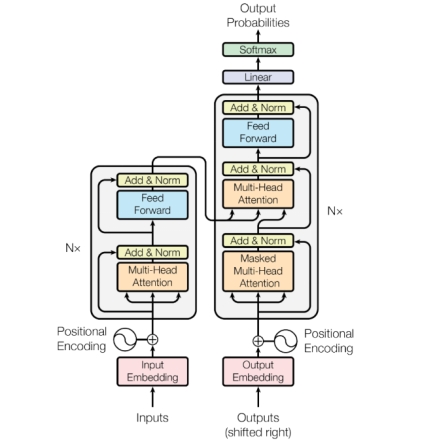
圖3-2 Transformer架構
Encoder和Decoder是由Multi-Head Attention多頭注意力層、Add&Norm殘差正則化層、Feed Forward全連接層組合堆疊而成,其中Multi-Head Attention是多個Self-Attention自注意力組成。整個計算公式如下:
![]()
![]()
自注意力機制在計算的時候需要用到矩陣Q(查詢)、K(鍵值)、V(值):
![]()
公式中在計算矩陣Q和K內積時,為了防止內積過大,因此除以dk的平方根。而多頭注意力是由多個自注意力組合形成,通過將每個自注意機制的輸出拼接在一起(Concat),然後傳入一個線性層,得到最終的輸出。多頭注意力的輸出和原始輸入相加是一種殘差連接,類似於ResNet中解決多層網絡訓練過擬合的問題,讓網絡只關注當前差異的部分。LayerNorm用於歸一化單個數據樣本中所有特徵的均值和方差,有利於序列化樣本以及批處理規模較小或動態的情況。全連接層包含兩層,第一層的激活函數為ReLU,第二層不使用激活函數。在本文研究中,僅適用Transformer的編碼器部分,對輸入的股票多因子特徵進行編碼,經過堆疊多層的多頭注意力和全連接層後將所有隱藏的因子特徵求和作為輸出,進行股票未來收益率的回歸。
4.研究實驗
4.1實驗設置
數據集:為了驗證資産配置的實證效果,我們對中國A股市場兩個主要股票指數(CSI300和A500)的成分股進行了測試,期望達到指數增強。值得注意的是,中國A股市場不允許空頭倉位,為了驗證因子組合模型的有效性,在實驗中假設A股允許空頭。數據被分為訓練集和測試集,如表4-1所述。由於缺少數據或者存在ST警告,一些公司實際會被剔除股票池。
表4-1 實驗數據統計分析
Index | #Stocks | Training | Test |
CSI300 | 300 | 2014.01-2021.12 | 2022.01-2024.04 |
A500 | 500 | 2014.01-2021.12 | 2022.01-2024.04 |
基準模型:對於LightGBM和Transformer,這類直接預測股票價格然後根據未來漲跌幅進行橫截面排序配置資産比例的模型,我們選取了等權因子組合模型(Eqw)、DNN、LSTM進行比較。
評估標準:我們利用六種評估指標來滿足投資者的不同風險偏好,如下:(1)利潤標準,包括年化收益率 (ARR)。(2) 風險標準,包括年化波動率 (AVol) 和最大回撤 (MDD)。(3) 風險利潤標準,包括年化夏普比率 (ASR)、卡爾瑪比率 (CR) 和索提諾比率 (SoR)。對於 AVol 和 MDD,較低的值是可取的;而對於 ARR、ASR、CR 和 SoR,較高的值是可取的。此外還引入了換手率衡量實際交易中的交易成本。
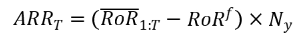
ARRT(Annualized Rate of Return)是一個持有周期的年化平均收益率,RoR 1:T是持有期的平均收益率,RoRf是無風險收益率,Ny是一年中持有周期的個數。
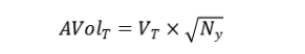
AVolT(Annualized Volatility)是年化平均波動率,反映了策略的風險水平。
![]()
MDDT(Maximum DrawDown)是衡量投資策略在最糟糕情況下的損失,ACi和ACj是在時間戳i和j下的累計資産凈值。
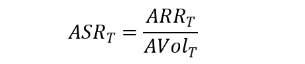
ASRT(Annualized Sharpe Ratio)是年化夏普率,基於年化波動率的風險調整收益。
TVRT(Turnover Ratio)是換手率,在T時期內的成交量和發行總股數的比值。
4.2實驗結果
4.2.1 LightGBM
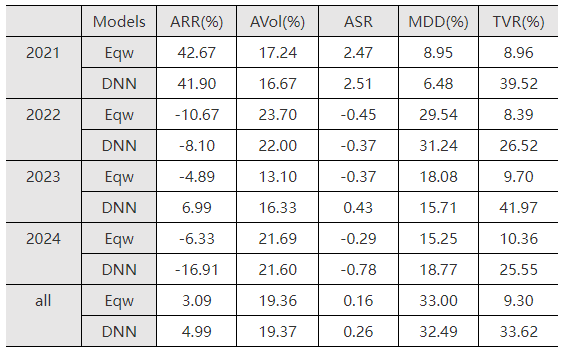
為了驗證機器學習算法是否能夠優化已有因子組合的資産配置,我們基於已有股票因子測試了LightGBM和多因子等權組合的效果。表4-2和表4-3分別展示了LightGBM和等權組合在滬深300和A500兩個指數成分股純多頭(按照因子組合結果排序取前50%的股票支數)的資産配置條件下收益和風險的表現。
整體來看LightGBM相比等權組合,在年化收益率、年化夏普率、最大回撤指標上結果更好,在年化波動率和換手率指標上結果稍遜。這表明機器學習算法可以改進傳統的資産配置結果,實現在風險可控條件下較高的收益。在2022、2023年市場低迷的情況下,LightGBM的資産組合能夠減少損失;在2021年市場行情好的情況下,LightGBM也能夠迅速捕捉熱點抓住賺錢效應;在2024年市場波動劇烈的情況下,LightGBM的組合表現可能不盡如人意,因此我們可以將LightGBM和已有的因子組合模型相結合,形成一個多樣化且魯棒性強的組合配置策略。
表4-2 LightGBM和因子等權線性組合的滬深300成分股組合結果
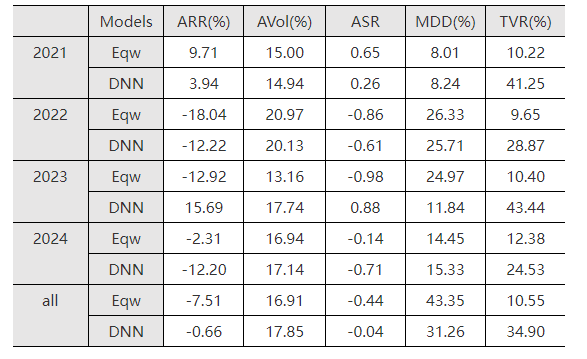
表4-3 LightGBM和因子等權線性組合的A500成分股組合結果
4.2.2 Transformer
為了激發深度學習模型的非線性擬合能力,我們嘗試了對已有因子的組合配置採取多層感知機DNN、基於注意力的長短記憶神經網絡ALSTM以及基於自注意力機制的Transformer三種深度學習算法,測試其在滬深300和A500上多頭組合的結果。如表4-4所示,三個深度模型和等權組合相比,在年化收益率、年化波動率、年化夏普率和最大回撤指標上結果更有,但是換手率更高,這表明機器學習算法能夠迅速捕捉市場熱點進行調倉。圖4-1和圖4-2展示了三種深度學習模型在滬深300和A500成分股組合上的凈值曲線,在2020-2023年左右,深度學習模型表現穩健回撤小,在2023-2024行情劇烈和橫幅振蕩的情況下表現優異,能夠減少投資者的損失。
通過在指數上的實證研究,基於LightGBM和Transformer算法的資産配置策略在市場波動較大的時期,投資組合的平均年化波動率較傳統資産投資有明顯改善,同時年化收益率保持在相對穩定且具有競爭力的水平,實現了風險與收益的有效平衡。
表4-4 DNN、ALSTM、Transformer在滬深300和A500上的資産組合結果
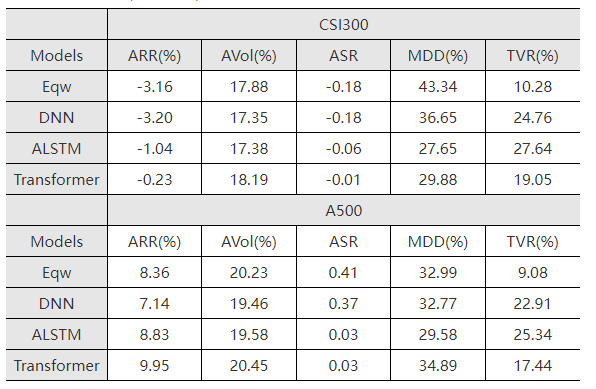
圖4-1 不同深度學習模型在滬深300成分股組合上的累計凈值
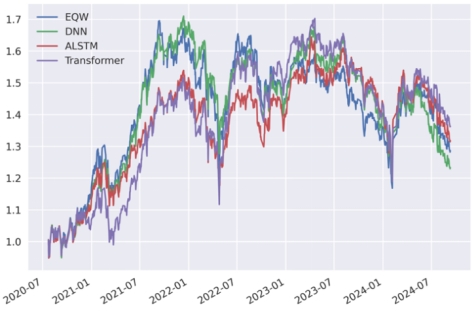
圖4-2 不同深度學習模型在A500成分股組合上的累計凈值
5.結論
本文在資産配置任務上,引入了各種機器學習和深度學習算法,並應用於中國A股市場。通過決策樹模型驗證了機器學習算法可以適應不同經濟形勢下的A股市場創造穩定的組合收益,相比手工構造因子組合提高了組合配置的效率;通過深度學習的Transformer模型應表明深度學習模型擁有更強的非線性擬合能力,可以構造出多樣化的因子組合結果。這證實了人工智能在為居民提供更全面準確的市場信息、個性化定制的資産配置方案、提高投資效率等多方面的價值。同時,人工智能技術對證券公司而言,可以輔助客戶行為分析,改善客戶的個性化資産投資方案,提升公司服務水平幫助居民更好地實現財富管理目標,踐行證券行業以人民為中心的理念。
參考文獻
[1] Perold, A.F., 2004. The capital asset pricing model. Journal of economic perspectives, 18(3), pp.3-24.
[2] Huberman, G., 2005. Arbitrage pricing theory (No. 216). Staff Report.
[3] Sharma, R. and Mehta, K., 2013. Fama and French: Three factor model. SCMS Journal of Indian Management, 10(2), p.90.
[4] Markowitz, H., 1952. Modern portfolio theory. Journal of Finance, 7(11), pp.77-91.
[5] Cheung, W., 2010. The black–litterman model explained. Journal of Asset Management, 11, pp.229-243.
[6] Ke, G., Meng, Q., Finley, T., Wang, T., Chen, W., Ma, W., Ye, Q. and Liu, T.Y., 2017. Lightgbm: A highly efficient gradient boosting decision tree. Advances in neural information processing systems, 30.
[7] Hochreiter, S., 1997. Long Short-term Memory. Neural Computation MIT-Press.
[8] Vaswani, A., 2017. Attention is all you need. Advances in Neural Information Processing Systems.
[9] Jiang, Z., Xu, D. and Liang, J., 2017. A deep reinforcement learning framework for the financial portfolio management problem. arXiv preprint arXiv:1706.10059.
[10] Wang, J., Zhang, Y., Tang, K., Wu, J. and Xiong, Z., 2019, July. Alphastock: A buying-winners-and-selling-losers investment strategy using interpretable deep reinforcement attention networks. In Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining (pp. 1900-1908).
[11] Wang, Z., Huang, B., Tu, S., Zhang, K. and Xu, L., 2021, May. DeepTrader: a deep reinforcement learning approach for risk-return balanced portfolio management with market conditions Embedding. In Proceedings of the AAAI conference on artificial intelligence (Vol. 35, No. 1, pp. 643-650).
[12] Niu, H., Li, S. and Li, J., 2022, October. MetaTrader: An reinforcement learning approach integrating diverse policies for portfolio optimization. In Proceedings of the 31st ACM international conference on information & knowledge management (pp. 1573-1583).
[13]李斌,屠雪永. 基於機器學習和資産特徵的投資組合選擇研究[J]. 系統工程理論與實踐,2024,44(1):338-355. DOI:10.12011/SETP2023-1784.
[14]雷明明. 基於長期資産價格預測的投資組合算法[D].山東財經大學,2023.
[15]方毅,陳煜之,衛劍. 人工智能與中國股票市場——基於機器學習預測的投資組合量化研究[J]. 工業技術經濟,2022,41(8):83-91. DOI:10.3969/j.issn.1004-910X.2022.08.011.
(作者:楊雨松,西南證券股份有限公司黨委副書記、總經理,高級經濟師;慕宗燊,西南證券股份有限公司博士後科研工作站研究人員)


